Eideticom Demonstrates Industry’s First NVMe over RDMA and TCP/IP using Broadcom’s NetXtreme Ethernet SoC: The Backstory
- Written by: Roger Bertschmann

I’m very excited to share some details about work we at Eideticom recently did with Broadcom, one of our NIC partners, which led to our latest news release. Here is the backstory on why NoLoad™ FPGA compute disaggregation running via Broadcom’s NeXtreme SOC as described in the press release is groundbreaking.
Broadcom launched the NetXtreme Ethernet SoC or BCM58800 at the Flash Memory Summit in August 2017. It’s an exciting product because it combines the functionality of a 100 Gb/s capable NIC with an eight-core ARM Cortex-A72 processor subsystem which is capable of running Linux among other things. Imagine building a low power, cost-efficient yet powerful storage array where the BCM58800 is not just the NIC but also is the host processor managing the attached NVMe SSD’s. An additional really powerful feature of the BCM58800 is that it supports NVMe over Fabrics (NVMe-oF) including both the existing RDMA and the soon to be finalized TCP/IP transport protocols.
NVMe-oF is a network protocol used to communicate between a host and a NVMe compliant storage system over a network like Ethernet or Infiniband. The great thing about it is that it enables disaggregation of storage resources because you can access and share your NVMe storage across the network. The RDMA transport protocol is typically used in High Performance Computing (HPC) or other high performance networks where latency is important but it definitely requires more specialized hardware and software to support it. TCP/IP on the other hand is ubiquitous as its supported by virtually every NIC and operating system and is the defacto transport protocol for networking across the internet. NVMe-oF currently supports RDMA transport and early adopters like Lightbits, Broadcom and Eideticom are working on standardizing and demonstrating TCP/IP support.
Here is the tie-in to what Eideticom is developing. Our NoLoad FPGA accelerator fits in nicely to storage networks because it a) looks like a NVMe storage device and as a result works with the inbox NVMe drivers on all operating systems and across all CPU architectures i.e. Intel, ARM, IBM, etc and b) provides CPU offload for analytics and storage i.e ML inference, data-tagging, compression etc. Because NoLoad identifies as an NVMe device and ties into the greater NVMe ecosystem we can work across fabrics using NVMe-oF. This means that an accelerator function in NoLoad i.e. Compression can be accessed by a remote client across a network like Ethernet. Now you have the ability to disaggregate compute resources on the NoLoad FPGA across a network fabric.
And here is the groundbreaking part. At SC17 we showcased the ability to do FPGA disaggregation using NVMe-oF and RDMA (summary video here by our awesome CTO, Stephen Bates). The new and exciting element in our work with Broadcom on the BCM58800 and NoLoad is that we were able to extend our FPGA disaggregation demo to work using TCP/IP transport.
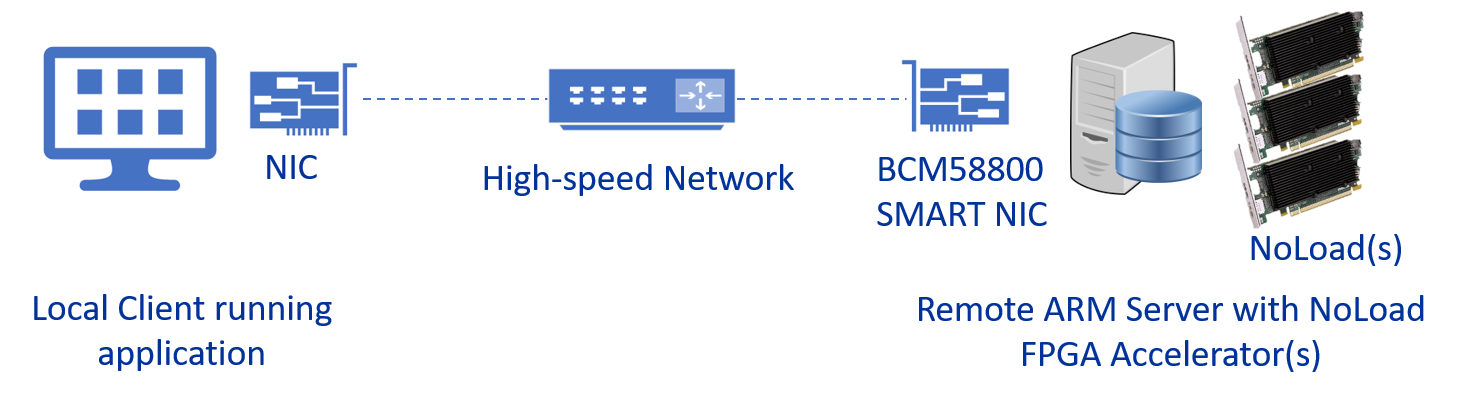
Now a NoLoad FPGA accelerator located in a remote server can be accessed by any client with a TCP/IP connection. NoLoad FPGA compute acceleration resources can now be easily shared across a network in a standard compliant way using TCP/IP with great performance.
Get your FPGA’s out of the box!
Thanks very much to Eliot Rosen, Fazil Osman and Velibor Markovski from Broadcom for supporting this work.