- Written by: Andrew Maier
Intro
In the world of high-performance Computational Storage, efficient data management and hardware access is critical. Libnoload is a robust software library API designed for seamlessly interfacing with NoLoad hardware platforms. It simplifies integration with NoLoad computational storage hardware and improves performance, saving developers significant time and resources. Libnoload handles all hardware interactions by leveraging the standard NVMe in-box driver. The included Command Line Interface (CLI) allows quick accelerator access as well as a suite of administrative capabilities such as firmware updates, status monitoring, and information logging. With the Libnoload software package, users can expect streamlined access to NoLoad acceleration and administrative features.
- Written by: Andrew Maier
Since the early days of P2PDMA in Linux kernel 4.20, enabling Peer-to-Peer (P2P) traffic has been a focus for Eideticom. In the age of AI applications and large datasets, efficiently moving stored data closer to processing has become increasingly important. The P2PDMA framework enables seamless data movement between PCIe devices without burdening host memory. As a fully open-source solution integrated into the upstream Linux kernel, it offers distinct advantages over competing proprietary technologies like GPUDirect [1].
Recently, there have been two significant development advances for P2PDMA in the kernel community. The development of a new userspace interface has been accepted upstream as of kernel v6.2 [2] which allows user applications to allocate and use P2PDMA memory. Most notably, this interface, alongside the entire kernel framework, has been enabled by default in Ubuntu 24.04 (Noble Numbat) [3] and adoption by other major distributions such as RHEL is on the horizon.
Host CPUs can utilize an NVMe Controller Memory Buffer (CMB) as a Direct Memory Access (DMA) target for P2P traffic. CMB is a region of memory exposed as a PCIe Base Address Register (BAR) by an NVMe compliant device. The available CMB exposed by all NoLoad NVMe Computational Storage products allows P2PDMA to be used without code changes by user applications running on modern kernels.
This post will outline the architecture of the P2PDMA framework and provides performance results gathered using standard in-box Linux tools while describing the test server setup. Potential applications of the CMB within the NoLoad framework will also be explored, offering insights into the tangible benefits of this cutting-edge technology.
Background of P2PDMA
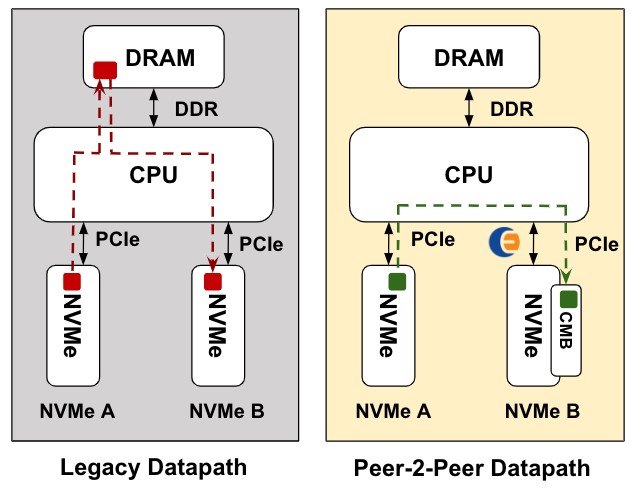
Figure 1 shows the difference between traditional (legacy) DMAs and DMAs using P2PDMA.
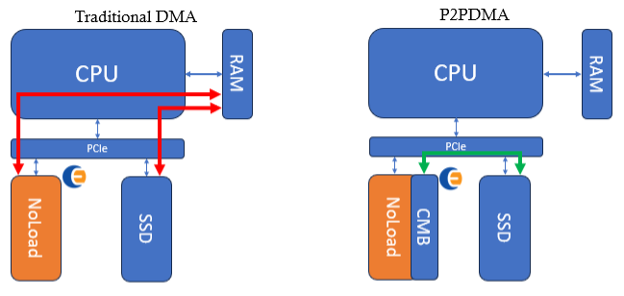
Figure 1: Traditional DMAs vs P2PDMA. This shows how the P2PDMA framework can entirely avoid the system memory (RAM)
Transfers that use the P2PDMA framework bypass the system memory (RAM) and instead use an exposed PCIe memory (such as the CMB of an NVMe compliant NoLoad device). In memory intensive applications, the system memory performance can become a bandwidth and latency bottleneck – the use of P2PDMA avoids this problem by moving data directly between peer PCIe devices. This functionality is available on modern root ports and CPU processors.
NVMe CMB integration into P2PDMA, like NVIDIA’s GPUDirect Storage, promises streamlined data processing and acceleration between NoLoad accelerators and storage devices.
NoLoad CMB Test
The test setup utilizes a server setup with Ubuntu 24.04, 4x PCIe Gen4 SSDs, and a NoLoad with a 512 MiB CMB implemented on a Bittware IA-440i Agilex-7 FPGA card. Figure 2 shows a block diagram of the server setup.
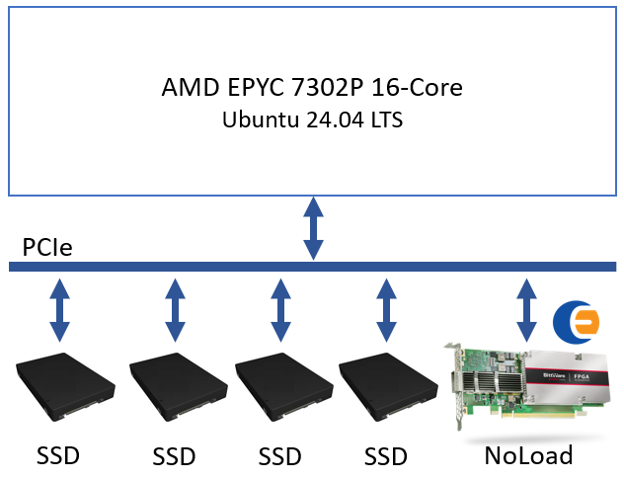
Figure 2: Block diagram showing the NoLoad P2PDMA test setup
Server: Lenovo ThinkSystem SR635 1U
CPU: AMD EPYC 7302P 16-Core Processor
System Memory: 512 GB (8 x 64 GB Lenovo DDR4 3200MHz ECC)
OS: Ubuntu 24.04 LTS (6.8.0-31-generic)
SSDs: 4x Samsung MZQL23T8HCLS-00A07 U.2 PCIe Gen4x4
NoLoad: Bittware IA-440I Agilex-7 AIC w/ 512MiB NVMe CMB
Traffic was generated from the DMA engines of the SSDs that targeted the CMB of the NoLoad using P2PDMA by a one-line FIO config change enabling the iomem option [4]. This gave the results in Figure 3.
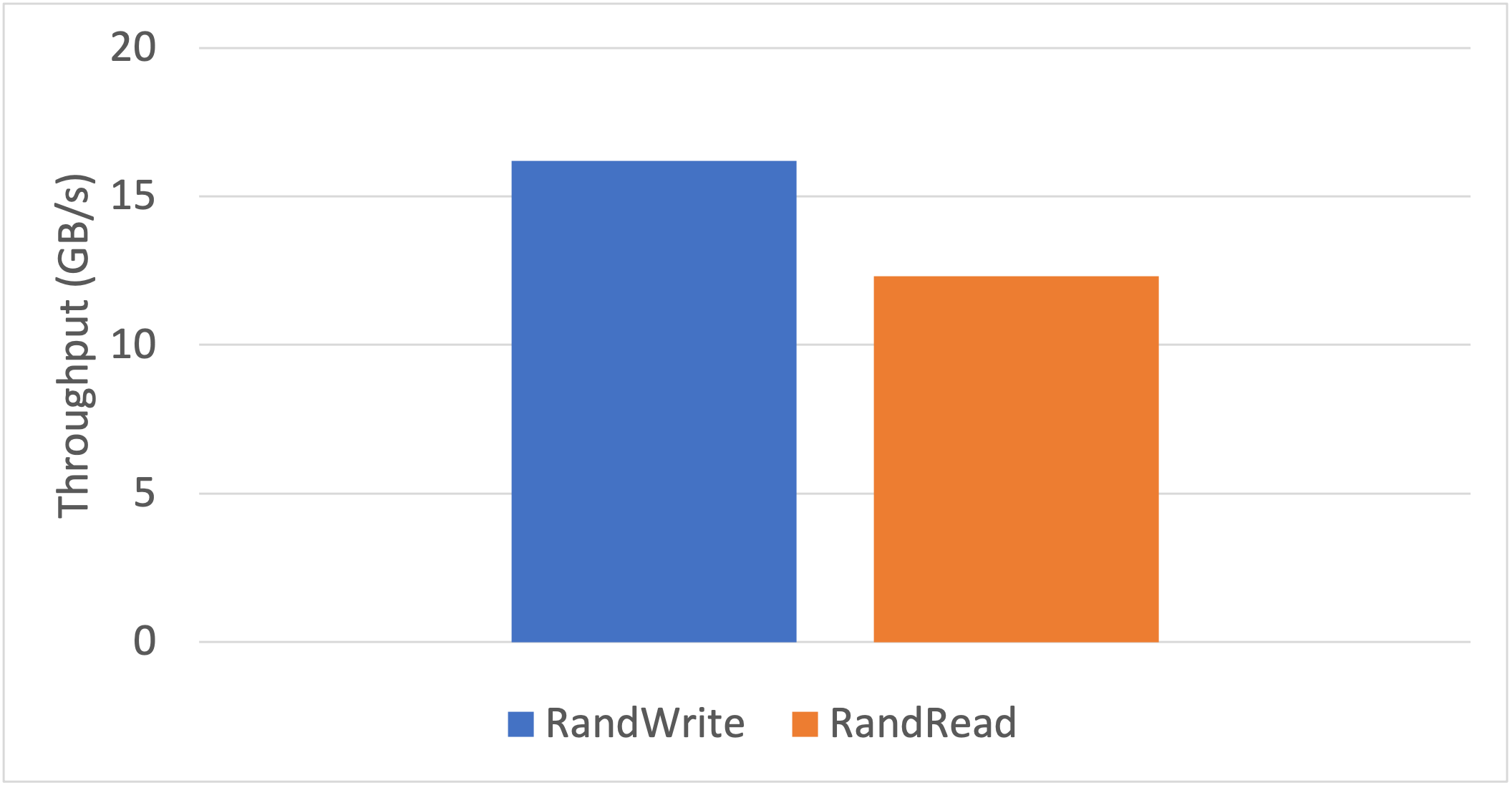
Figure 3: Performance results of DMA transfers between 4 SSDs and the NoLoad CMB.
The maximum random write throughput from the SSDs to the NoLoad CMB via P2PDMA was measured to be 16.3 GB/s. The maximum random read performance from the NoLoad CMB to the SSDs was measured to be 12.6 GB/s. Note, reads and writes are from the perspective of the CMB.
The maximum throughput performance of the P2PDMA test was limited by the dual DDR4 banks on the IA-440I card, not by the P2PDMA framework. This result shows that high bandwidth data transfers between SSDs and the NoLoad CMB can be achieved without using system memory, freeing up the bandwidth for other tasks.
Conclusion
In summary, P2PDMA, now enabled by default in Ubuntu 24.04, provides an open-source, vendor-neutral alternative to proprietary solutions (such as GPUDirect) for transferring data without utilizing system memory. The full functionality of upstream open-source P2PDMA was demonstrated by this test using NoLoad’s NVMe Compliant CMB.
Testing demonstrated the ability to achieve high bandwidth data transfers between storage devices and NoLoad while entirely avoiding the system memory of the CPU.
Takeaways
- By leveraging the P2PDMA framework, which is in upstream Linux and enabled by default in Ubuntu 24.04 LTS, PCIe traffic between devices can be offloaded completely from system memory. Now there is an upstream, open-source, and vendor-neutral solution for enabling P2P data transfers!
- Eideticom’s NoLoad NVMe Computational Storage Processor (CSP) provides an NVMe complaint CMB, enabling P2PDMA transfers with exceptional performance.
- Utilizing P2PDMA with NoLoad enables the direct pipelining of accelerator functions with data provided to/from SSDs, thereby alleviating the load on system memory and optimizing data flow.
Next Steps
In upcoming blog posts, we will explore further applications, such as integrating with a network card (NIC), pipelining acceleration functions, and implementing the NoLoad CMB in High Bandwidth Memory (HBM).
Contact Eideticom (
References
|
[1] |
"GPU Direct," [Online]. Available: https://developer.nvidia.com/gpudirect. |
|
[2] |
"Peer-to-peer DMA," [Online]. Available: https://lwn.net/Articles/931668/. |
|
[3] |
"Ubuntu Launchpad," [Online]. Available: https://bugs.launchpad.net/ubuntu/+source/linux-oem-6.0/+bug/1987394. |
[4] FIO config:
[global]
runtime=1h
time_based=1
group_reporting=1
ioengine=libaio
bs=1M
iomem=mmapshared:/sys/class/nvme/nvme2/device/p2pmem/allocate
iodepth=16
direct=1
zero_buffers=1
[p2p-read]
rw=read
numjobs=16
- Written by: Sean Gibb
We are excited to announce the production release of Eideticom’s Transparent Compression solution on our partner BittWare’s IA-440i Add-in Card with Intel Agilex-7 FPGA. In this blog we will be providing a summary of features/performance and why it’s important. As a quick background, Eideticom offers market-leading storage acceleration services for compression, encryption and data analytics. At Eideticom we have worked to address the computational storage market through our NoLoad solution which offers a promising avenue for customers to offload their CPUs for essential business functionality.
- Written by: Andrew Maier
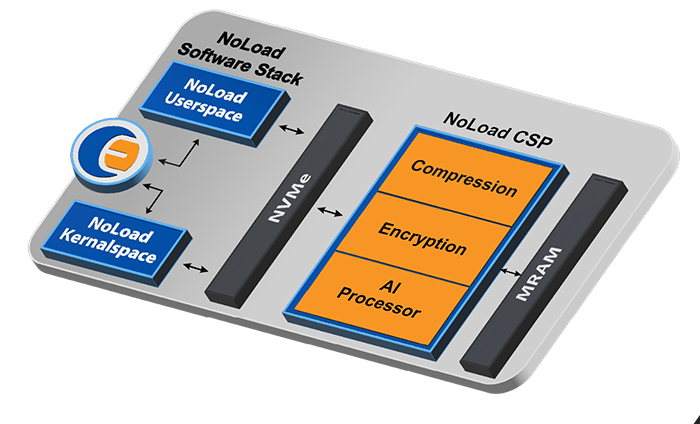
Our partner Avalanche Technologies is showcasing the NoLoad® NVMe Computational Storage Processor (CSP) as an interface for the SpaceVPX platform at the SmallSat Symposium in Mountain View, CA, in conjunction with Trusted Semiconductors, Blue Halo, and Mercury Systems. The Space Drive combines the performance benefits of Eideticom’s NoLoad® Computational Storage Platform with Avalanche’s flagship Space Grade MRAM offering, STT-MRAM and specifically targets AI computing in space. Eideticom’s NoLoad platform is an innovative standards-based NVMe CSP solution to support increasing demand from the defense and commercial space communities for computation and storage. With its virtually infinite endurance, radiation resilience and compelling densities, Avalanche’s STT-MRAM provides a robust low latency storage technology for the rigors of space.
- Written by: Stephen Bates

At Eideticom we are incredibly excited by NVMe Computational Storage. Our existing NoLoad® products use NVMe to connect accelerators to applications, this provides our customers with an end-to-end computational storage solutions. Our customers see value in a rich, open-source, vendor-neutral software ecosystem for computational storage and that's what standards like NVMe can enable.
- Written by: Stephen Bates

We had a busy couple of weeks at Eideticom recently with Open Compute (OCP) Summit and the NVM Express Annual Meeting back-to-back. In this blog I wanted to fill you in on some of our activities at those two events.
- Written by: Super User

Eideticom is a leader in Computational Storage! Computational Storage is a new computer architecture initiative that aims to improve the performance, efficiency and cost of computer systems by moving computation tasks closer to the storage layer.
In this blog we will look back on a great 2018 for the Computational Storage initiative and look forward to 2019 and discuss some of the things we expect to see.
- Written by: Stephen Bates
On Sunday November 4th 2018 Linus Torvalds released the first candidate for the 4.20 Linux kernel and it includes the upstream version of the Eideticom Peer-to-Peer DMA (p2pdma) framework! This framework is an important part of the evolution of PCIe and NVM Express Computational Storage as it will allow NVMe and other PCIe devices to move data between themselves without having to DMA via CPU memory.
- Written by: Super User

Every year SNIA holds an event called Storage Developers’ Conference in San Jose. This year’s event was, as usual, an excellent technical conference attended by a Who’s Who of the storage architect world. As well as having excellent technical tracks this event is renowned for its networking with plenty of opportunities for hallway and bar conversations.
- Written by: Stephen Bates

In a previous blog I was very pleased to announce that Eideticom, in partnership with Xilinx, IBM and Rackspace, performed the first public demo of NVM Express at PCIe Gen4. In this blog I’d like to give a Mellanox ARM64 update to that work and tie it into the bringup of our U.2 NoLoadTM!
- Written by: Stephen Bates

I recently spoke at the NVMe Members forum on a topic near and dear to my heart. The topic was “Enabling the NVMe CMB and PMR Ecosystem” and was given with Oren Duer, Director of Storage Software at Mellanox. You can click on the links to the presentation and even better a link to a video recorded at the event.
- Written by: Stephen Bates
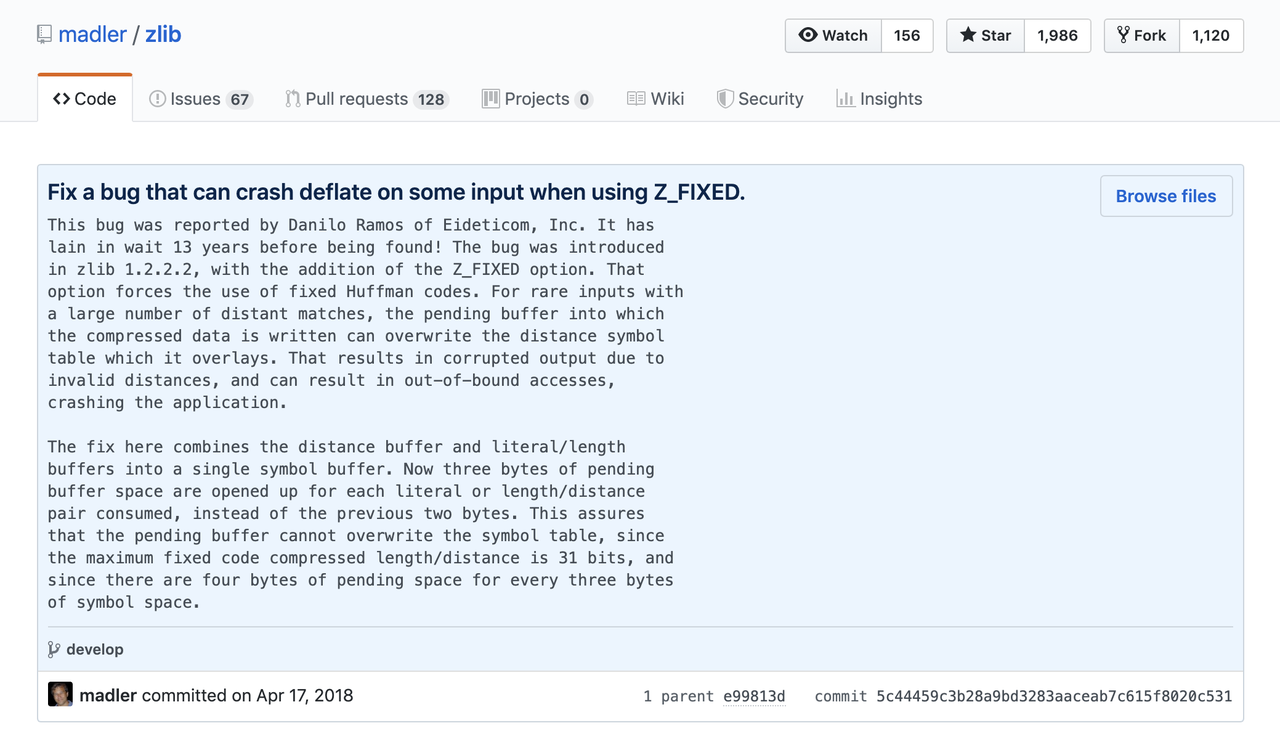
We take verification of our IP very seriously at Eideticom. While running test-benches against our new compression RTL core for our NoLoad NVMe accelerator we hit a bug. Turns out the bug was actually in the software version of zlib, a software library used for data compression and had lain in the code for 13 years. We reported the bug to Mark Adler and he pushed a fix to GitHub! Nice work Danilo Ramos, MSc, P.Eng and the others on the Eideticom team for tracking this down.
Here is the link to Mark’s zlib update on github: https://github.com/madler/zlib/commit/5c44459c3b28a9bd3283aaceab7c615f8020c531
If you are interested in deploying offloaded compression in your NVM Express based systems give me a shout because the Eideticom NoLoad could be perfect for you!
- Written by: Stephen Bates, CTO
In this blog we are very pleased to announce, the U.2 version of our NoLoad™ NVM Express (NVMe) computational storage and offload engine. Working with our friends at Nallatech we have developed a ground-up solution for NVMe based offload for storage and analytics in a form-factor that is ideal for next-generation, NVMe based, storage and compute systems. We are very happy to have Allan Cantle (CTO and Founder at Nallatech, a Molex company) act as a co-author on today’s blog. Nallatech are our hardware partner in the development of the U.2 NoLoad™.
- Written by: Stephen Bates, CTO
I mentioned in my last blog that NVM Express (NVMe) is fast. Today it got even faster as we demonstrate, what we believe, is the first public domain demo of NVMe running over PCIe Gen4. This doubles the throughput of NVMe and allows systems built around NVMe to achieve performance levels that have been unobtainable before now.
- Written by: Stephen Bates, CTO
On February 14th Eideticom pushed some code into upstream Storage Performance Developers Kit (www.spdk.io and https://github.com/spdk/spdk) that enables new and interesting capabilities related to NVM Express (NVMe) SSDs with Controller Memory Buffers (CMBs). In this article I take a closer look at why we did that and why it’s good for the producers and users of NVMe devices.
- Written by: Roger Bertschmann
I’m very excited to share some details about work we at Eideticom recently did with Broadcom, one of our NIC partners, which led to our latest news release. Here is the backstory on why NoLoad™ FPGA compute disaggregation running via Broadcom’s NeXtreme SOC as described in the press release is groundbreaking.